Note
This technote is a work-in-progress.
1 Abstract¶
The Data Management (DM) subsystem provides key systems for Summit operations. This document enumerates them and their interactions with systems provided by the Camera and Telescope & Site subsystems.
It differs from DMTN-111 in addressing DM-provided components and infrastructure expertise as well as being focused on the information flows rather than the use of Science Pipelines code.
DM directly provides services such as the Summit RSP, OODS, Sasquatch, OCPS, CDB, and Prompt Processing. DM provides data such as combined calibration images and defect maps. And DM provides the Science Pipelines code for image processing that is used in services such as Active Optics, RubinTV, and Rapid Analysis. DM also participates in the Summit architecture by providing expertise in infrastructural systems like Kubernetes, Kafka, InfluxDB, PostgresQL, ArgoCD, and Phalanx.
2 Overall Summit Computing Architecture¶
The Summit is primarily composed of systems, known as CSCs (Commandable SAL Components), communicating via messages sent by the SAL library. Today these messages are implemented via a DDS message bus, but this will be changing soon to an Apache Kafka implementation. These messages include commands, events (at irregular intervals), and telemetry (at regular intervals). Many of these components communicate directly with hardware systems or talk via non-SAL means to lower-level control computing elements that do so. Some CSCs control or monitor others; these include the Scheduler, ScriptQueue, LOVE, and Watcher.
All SAL messages are translated to Kafka and inserted into an InfluxDB time-series database known as the Engineering and Facilities Database (EFD) which is part of the Sasquatch time-series metrics system. (This translation will no longer be necessary when the SAL reimplementation is deployed.)
The CSCs are deployed on top of Kubernetes using ArgoCD. The Summit Kubernetes cluster is named “yagan”.
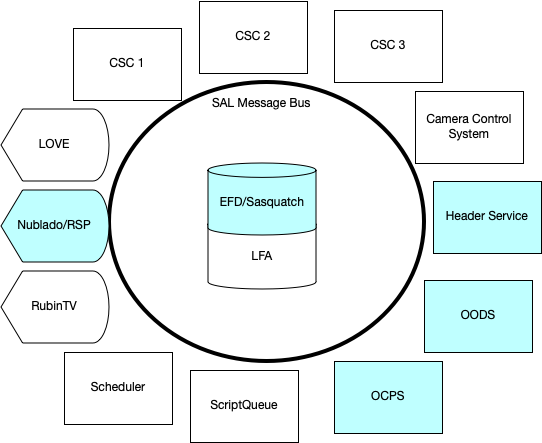
Figure 1 Overview of the Summit showing components interacting via the SAL message bus.¶
3 Information Flows¶
3.1 Operator commands¶
Operators primarily control the CSCs via the LOVE (LSST Operations and Visualization Environment) tool. Typically, procedures are executed as scripts submitted to the ScriptQueue CSC. The Scheduler can automatically submit scripts to the ScriptQueue. But custom procedures are executed via Jupyter notebooks running on the Summit RSP. That RSP instance is supported by DM, but it deploys containers that are generated by Telescope & Site Software (TSSW) using DM Science Platform containers as a base.
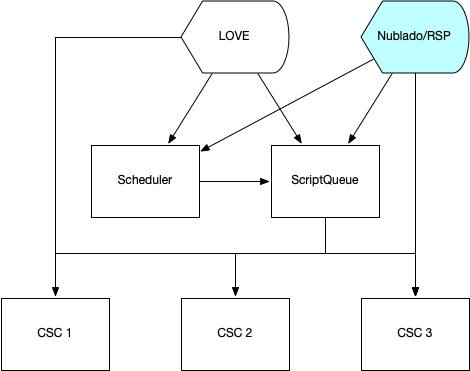
Figure 2 Information flow for operator commands.¶
3.2 CSC monitoring¶
Operators monitor CSCs by means of displays in LOVE. Charts in Chronograf also are used to monitor EFD parameters obtained from events or telemetry.
The Watcher CSC can detect particular events or trigger on telemetry parameters going out of a range, alerting operators via LOVE.
Alarms can be automatically distributed to support teams via the Squadcast on-call and incident response platform.
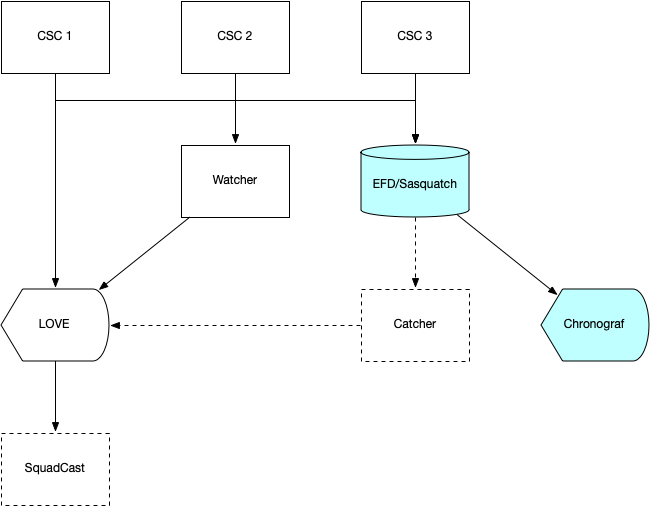
Figure 3 Information flow for operator monitoring.¶
3.3 Science data monitoring¶
Operators monitor the science quality of the image data by means of displays in RubinTV and metrics computed by the OCS-Controlled Pipeline Service (OCPS), Rapid Analysis, and Prompt Processing (at the USDF) that will be viewed in Chronograf.
At the Summit, the images are transferred from the Camera Control System (CCS) to the Observatory Operations Data Service (OODS), where they are ingested into a Butler repo. The OODS emits SAL events that tell Summit systems that an image is available. There is one OODS and Butler repo per instrument in order to keep these essential services independent of each other. The OODS storage is currently on a locally-attached disk volume exported via NFS, but it may change in the future to a Kubernetes NFS volume or an S3 object store (implemented with Ceph).
Raw images get their header metadata from the Header Service. This CSC gathers the values of specified items in SAL events and telemetry at specific times (startIntegration and endOfImageTelemetry) and publishes them as JSON suitable for transformation into a FITS header. The JSON file is published to the LFA. The CCS retrieves this file and formats the FITS header.
RubinTV is developed by the SIT-Com team. It performs “best-effort” ISR on the image, computes several instrument-specific metrics and plots based on the image and EFD telemetry, and displays them via an Internet-accessible Web interface.
The OCPS is a CSC that accepts commands, typically from the ScriptQueue but also from notebooks, to execute specified pipelines on data selected by a query expression from an OODS-managed Butler repo. There is one OCPS per instrument. The OCPS uses the standard IVOA UWS framework to manage its pipeline jobs and return results, which can be selected by dataset type. An additional feature tells the OCPS to wait until a list of prior jobs have completed before starting this one. This permits calibrations to be processed in sequence while still having jobs submitted as soon as possible after relevant images have been taken. If a workflow graph system were used instead, none of the processing could start until all images were ingested.
The Rapid Analysis system has requirements that have been defined by the FAFF working group to process science images and metadata and display images, plots, and metrics based on them. We are currently deciding whether it will be better to build this processing within the RubinTV framework, the Prompt Processing framework, or a combination of both.
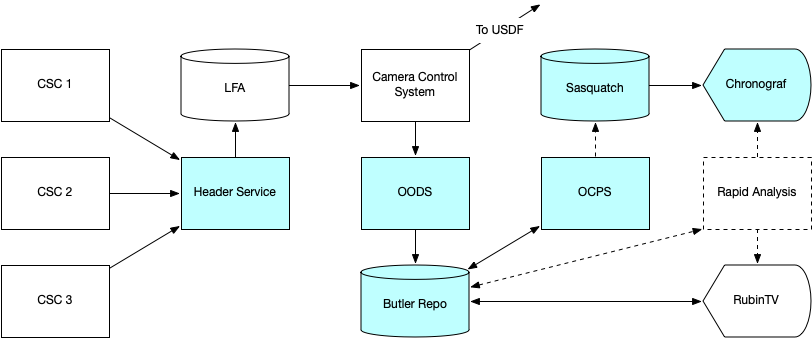
Figure 4 Information flow for science data.¶
3.4 Science data archive and processing¶
In addition to copying science images to the OODS, the CCS also transmits them via an S3 interface to the USDF Embargo rack. There, the Embargo Butler auto-ingest service ingests them into the Embargo repo and defines visits. These images are secured and available only to staff and Prompt Processing during the embargo period (30 days for Commissioning data, 80 hours for Operations data).
The Prompt Processing framework operates at the USDF, but it is tied to the Summit by the nextVisit event that is its trigger, allowing it to preload and precompute data before science images arrive; by the science images themselves, which are processed through pipelines; and by the return of key metrics to the Summit for use by LOVE, Chronograf, and operators. The metrics computed at the USDF will be transmitted back to the Summit via the Sasquatch Kafka mechanism, which is available via a REST interface. This mechanism is the sole means of near-realtime USDF-to-Summit data transfer. The only other automated USDF-to-Summit data transfer will be for combined calibration datasets, which will be transferred via Rucio (currently manually copied and ingested).
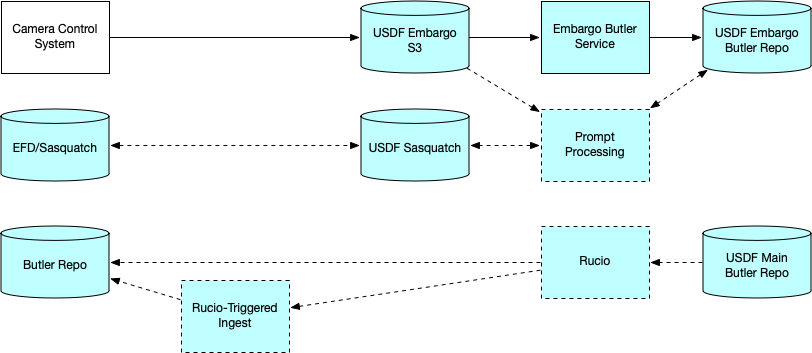
Figure 5 Information flow for science data to the USDF.¶
3.5 Science metadata¶
CSCs publish information to the EFD via their commands, events, and telemetry flowing as SAL messages. The EFD is replicated to a Sasquatch instance at the USDF via Kafka streams.
The Large File Annex (LFA) is conceptually part of the EFD, but its metadata is not suitable for storage in InfluxDB. Instead, it uses an S3 object store at the Summit that will be replicated to the USDF. Any CSC can place information in the LFA. Some datasets (often images) are suitable for Butler ingest. These include images from the star tracker cameras and the all-sky camera. Others may not be, such as PDF files. The OODS and the science image auto-ingest system will be adapted to ingest appropriate dataset types into the OODS repo and the USDF main repo. Note that currently the all-sky camera images are replicated to the USDF via an older mechanism, the Data BackBone Buffer Manager (DBBBM).
Operators may provide information about their experiences through three systems: a narrative log, an exposure annotation log, and Jira for failures and problems.
Scheduler information about upcoming visits will be published to the world via a Web site and an ObsLocTAP database query service.
Information about exposures that have been taken is currently published via a TAP service using the ObsCore schema, derived from the OODS Butler repo’s Registry. This information will be combined with exposure-specific summaries of EFD parameters, along with visit and log inforamtion, in the Consolidated Database (CDB). The CDB will be replicated to the USDF, where it can be augmented by metrics computed by Prompt Processing and Data Release Productions as well as data quality annotations.
The CCS maintains an internal telemetry database for use by Camera-specific tools, but its information is also replicated via SAL messages to the EFD. Another internal database maintains information about each image taken. This exposure database will be merged with the CDB.
Log files from all services running at the Summit are (or will be) collected by a central IT-provided service that will allow querying and detection of problems.
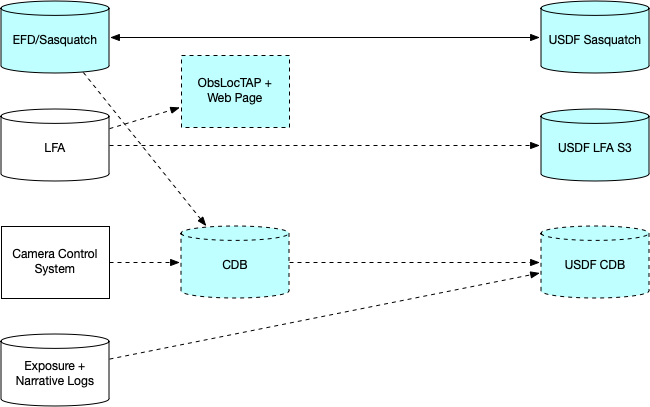
Figure 6 Information flow for science metadata to the USDF.¶